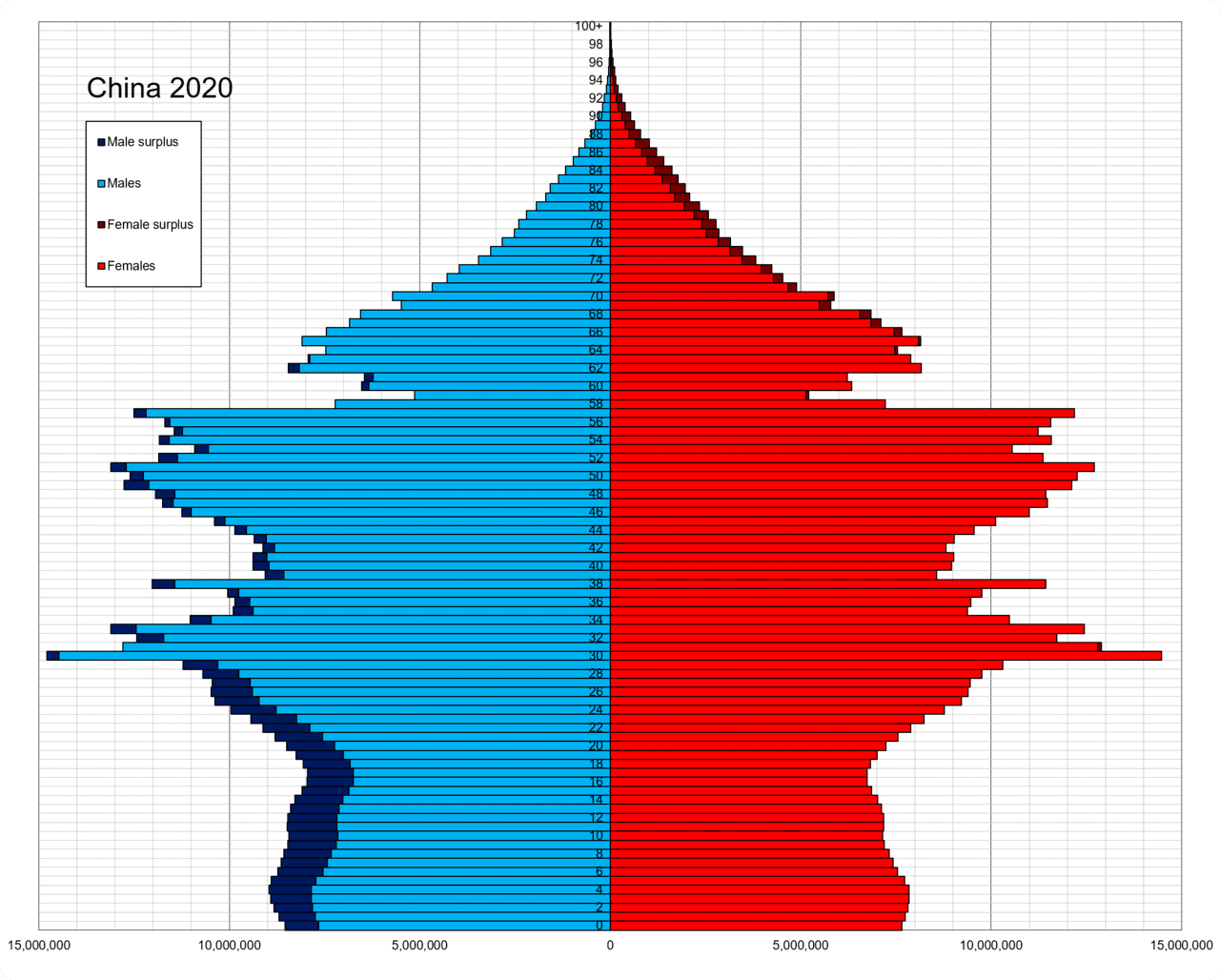
求解质数和斐波那契数
质数和斐波那契数列之间并没有直接的数学关系或依赖关系。质数和斐波那契数列是两个独立的数学概念,描述了不同的数学性质。
质数: 质数是大于1且只能被1和自身整除的正整数。例如,2、3、5、7等都是质数。质数在数论中有着重要的地位,并涉及到诸多有趣的性质和研究领域。
斐波那契数列: 斐波那契数列是一个数学序列,其定义是从第三项开始,每一项都是前两项的和。形式上,斐波那契数列可以表示为:F(n) = F(n−1) + F(n−2),其中 F(0)=0, F(1)=1。
虽然在数学上它们没有直接的联系,但在一些编程和算法问题中,可能会出现同时涉及到质数和斐波那契数列的情况。例如,一些算法问题可能要求同时判断某个数是不是质数,同时它的斐波那契数列中的位置是否也是质数。这种联系通常是在特定问题背景下引入的,而不是数学本身的关系。
质数
许多年前在 编程随想 的博客读到过文章 求质数算法的 N 种境界- 试除法和初级筛法,当时就感慨自己的思路不够开阔,作者在文章中分别给出了算法和数据结构的使用境界,总结如下:
一般人的思路是通过试除法来计算质数,然而筛法计算速度更为优越:
- 试除法:
- 境界1:最简单的试除法,从2一直尝试到x-1,效率最差。
- 境界2:优化为尝试到x/2,减少工作量。
- 境界3:只尝试奇数,因为质因数除2外都是奇数。
- 境界4:尝试到√x,因为成对的因数一个小于等于√x,另一个大于等于√x。
- 境界5:尝试小于√x的质数,以空间换时间,提高效率。
- 埃拉托斯特尼筛法(Sieve of Eratosthenes):
- 基本思想是从小到大枚举每个数,将其所有的倍数标记为合数。通过不断筛去合数,剩下的即为质数。
- 在第一次枚举时,标记所有的合数。
- 在后续枚举中,如果当前数没有被标记,那么它就是质数,然后标记其所有的倍数。
- 筛法的优化考虑:
- 如何确定质数的分布范围,涉及素数定理的应用。
- 如何设计存储容器,从整型容器到按位存储的布尔型容器,以提高空间性能。
在数据结构的使用上,也分为多重境界:
境界1:整型容器
- 设计: 使用整型数组,每个元素表示一个自然数,通过标记是否为质数。
- 特点: 简单直观,但浪费内存空间,可能导致频繁的内存分配和释放。
- 适用场景: 适用于小范围的质数筛选。
境界2:布尔型容器
- 设计: 使用布尔型数组,每个元素表示一个自然数,通过标记是否为质数(true表示是质数,false表示是合数)。
- 特点: 减少了内存浪费,避免了频繁的内存分配和释放。
- 适用场景: 适用于中等范围的质数筛选,相比境界1更节省内存。
境界3:按位存储容器
- 设计: 使用字节数组,每个字节存储多个自然数的质数信息,通过位运算标记是否为质数。
- 特点: 进一步减少了内存占用,提高了空间利用率,适用于大范围的质数筛选。
- 适用场景: 适用于大规模的质数筛选,具有更高的空间性能。
总体比较:
- 境界1最简单,但内存浪费大,性能差。
- 境界2减少了内存浪费,性能相对较好,适用于中等规模的问题。
- 境界3在内存占用上进一步优化,适用于处理大规模的问题。
在实际应用中,选择合适的境界取决于问题规模和性能需求。随着问题规模的增加,通常会选择更高境界的容器以提高性能。
斐波那契数列
在开源电子书《Hello算法》的 迭代与递归 章节中,给出了递归实现斐波那契数列的代码
1 | /* 斐波那契数列:递归 */ |
然而质数计算一般不适合使用递归。递归是一种自调用的方式,适用于问题可以分解为相同类型的子问题的情况。然而,质数判定本质上是一个简单的判断问题,没有自然地分解为相同类型的子问题。
质数判定通常采用迭代的方式,例如试除法或更高效的算法。递归可能会导致效率低下,因为它需要在每一层递归调用中保存状态,而这种方式可能会在处理大数时导致栈溢出或效率低下。
算法求解
ChatGPT 对于算法题“判断某个数是不是质数,同时它的斐波那契数列中的位置是否也是质数” 给出的求解步骤是:
- 判断数是否是质数: 使用常见的质数判定方法,例如试除法或更高效的算法(如 Miller-Rabin 算法)。如果数是质数,进入下一步;否则,停止判断。
- 确定数在斐波那契数列中的位置: 计算斐波那契数列,找到该数在序列中的位置。可以使用迭代或递归的方式计算斐波那契数列。
ChatGPT给出判断质数的代码是境界4,因为不需要使用额外空间复杂度存储所有质数
1 | import java.util.ArrayList; |